
GNU Bison 3.7 bringt Gegenbeispiele
by Viktor Garske on Sept. 15, 2020, 10:20 p.m., with 2 commentsEs gibt in der Informatik extrem spannende Gebiete, auf die wir täglich zurückgreifen, aber mit denen die Wenigsten direkt zu tun haben. Trotzdem ist es sehr kurzweilig, einen kleinen Einblick in diese Welt zu erhalten. Eines dieser Gebiete ermöglicht es, Informationen strukturiert und menschenleserlich darzustellen: es geht um (formale) Grammatiken. Grammatiken sind die Grundlagen für Sprachen und definieren, wie z. B. eine Rechenaufgabe, eine Konfigurationsdatei oder ein Quellcode aussehen dürfen. Während in einer Grammatik also definiert wird, wie etwas korrekt aussieht, ist das Pendant dazu der Parser, der eine Eingabe einliest, entscheiden kann, ob diese ein gültiger "Satz" in der Grammatik ist und anschließend zur Weiterverarbeitung vorbereitet. Diese Kombination aus Sprache und Parser ist im Grunde eine Schnittstelle zwischen Mensch und Maschine. Sie ermöglichte eine der entscheidendsten Produktivitätssteigerungen, da hierauf praktisch alle Programmiersprachen basieren und selbst einfachste Anwendungen wie Rechenaufgaben mit Hilfe von Grammatiken implementiert werden.
Nun sind Grammatiken ein gut erforschtes Gebiet: die Linguistik hat viel Forschung in den 1960er-Jahren reingesteckt und die Informatik hat diese automatisiert. Seit vielen Jahrzehnten gibt es sog. Parsergeneratoren, in die man einen Bauplan, die Grammatik, eingibt und welche dann einen fertigen Parser auswerfen. yacc war einer der bekanntesten Parsergeneratoren und wurde auf den meisten Systemen bereits von GNU Bison abgelöst. GNU Bison ist vor einigen Wochen in Version 3.7 erschienen und bietet eine interessante Möglichkeit, um Grammatiken zu debuggen. Ja, Grammatiken können „Bugs“ enthalten und ihr könnt euch vorstellen, dass es nicht ganz leicht ist, eine Lösung zu finden, wenn C++-Code oder eine JSON-Eingabe auf einmal nicht eingelesen werden können, weil der Parser XY einen Fehler hat.
Um es einfach zu halten, werde ich das kurz anhand des „Hello worlds“ der Parser, dem Taschenrechner, demonstrieren.
Eine Bison-Grammatik sieht in etwa so aus:
%{
#include <stdio.h>
int main(void);
int yylex(void);
void yyerror(char const *);
%}
%token ZAHL
%token ZEILENENDE
%%
start:
%empty
| start berechnung
;
berechnung:
strichrechnung ZEILENENDE { printf("= %d\n", $1);}
| ZEILENENDE /* ignore */
;
strichrechnung:
punktrechnung
| strichrechnung '+' punktrechnung { $$ = $1 + $3; }
| strichrechnung '-' punktrechnung { $$ = $1 - $3; }
;
punktrechnung:
ZAHL
| strichrechnung '*' ZAHL { $$ = $1 * $3; }
;
%%
int main(void)
{
yyparse();
}
void yyerror(char const *s)
{
fprintf(stderr, "Error: %s\n", s);
}
Den Lexer, der die Eingabe vorverarbeitet und entscheidet, was nun eine "ZAHL" ist, lasse ich der Einfachheit mal raus.
Interessant ist der Teil in der Mitte, da wird einerseits definiert, wie ein gültiger „Satz“ in unserer „Sprache der Rechenaufgaben (ohne Division)“ aussieht und daneben festgelegt, wie diese verarbeitet werden. So eine Bison-Grammatikdatei vermischt zwar ein wenig Syntax und Semantik, aber man will ja auch fertig werden. Die kleingeschriebenen Beizeichner heißen "Nichtterminale", sind ähnlich wie Variablen und können ausgetauscht werden. Die großgeschriebenen Bezeichner heißen "Terminale" und sind in unserem Beispiel Zahlen sowie das EOL/Enter. Eine Eingabe wäre also 2 + 5 * 2 <ENTER> bzw. 2 + 5 * 2 \n, da \n das Zeichen ist, was bei einem Enter entsteht. (Unter Linux zumindest) Das sieht visualisiert folgendermaßen aus:
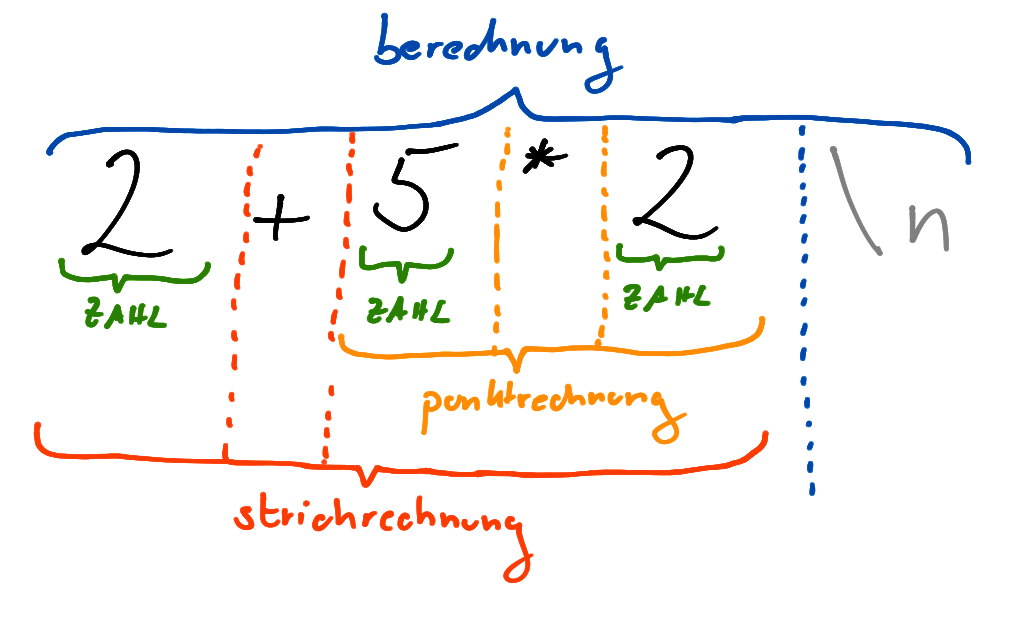
Wir sehen also, dass Grammatiken nebenbei auch die Punkt- vor Strichregel implementieren. Und das ist im Grunde auch das Hauptarbeitsfeld, wenn man an Parsern baut. Und eine große Fehlerquelle. Findet ihr den Fehler in der obigen Grammatik?
Bison meckert jedenfalls über 6 Reduzier/Reduzier-Konflikte, kann also bei bestimmten Eingaben nicht entscheiden, wie die Eingabe interpretiert werden soll. Bisher musste man selber die Grammatik mit Hilfe des zugrundeliegenden Automaten debuggen, aber nun kann Bison selber konkrete Beispiele liefern, an welchen Stellen nicht entschieden werden kann.
Diese Funktion lässt sich mit der Option -Wcounterexamples aufrufen und liefert für obige Grammatik:
parse.y: warning: reduce/reduce conflict on tokens '+', '-', '*' [-Wcounterexamples]
Example: strichrechnung '+' punktrechnung • '*' ZAHL
First reduce derivation
strichrechnung
↳ strichrechnung '+' punktrechnung
↳ strichrechnung '*' ZAHL
↳ punktrechnung •
Example: strichrechnung '+' punktrechnung • '*' ZAHL
Second reduce derivation
strichrechnung
↳ punktrechnung
↳ strichrechnung '*' ZAHL
↳ strichrechnung '+' punktrechnung •
parse.y: warning: reduce/reduce conflict on tokens '+', '-', '*' [-Wcounterexamples]
Example: strichrechnung '-' punktrechnung • '*' ZAHL
First reduce derivation
strichrechnung
↳ strichrechnung '-' punktrechnung
↳ strichrechnung '*' ZAHL
↳ punktrechnung •
Example: strichrechnung '-' punktrechnung • '*' ZAHL
Second reduce derivation
strichrechnung
↳ punktrechnung
↳ strichrechnung '*' ZAHL
↳ strichrechnung '-' punktrechnung •
Mit geschultem Blick wird das Problem deutlich: die Operatorrangfolge, das "Punkt vor Strich", ist nicht korrekt implementiert. Bison kann also nicht entscheiden, ob "2 + 5 * 2
punktrechnung:
ZAHL
| punktrechnung '*' ZAHL { $$ = $1 * $3; }
;
So kann die Grammatik eindeutig "interpretiert", also geparst werden und der Taschenrechner funktioniert.
Ihr könnt ja in den Kommentaren mal schreiben, ob euch das Thema interessiert und ob ich in weiteren Blogartikeln Aspekte und Grundlagen aus der Welt der Sprachen und Grammatiken aufbereiten soll. ;-)

Viktor Garske
Viktor Garske ist der Hauptautor des Blogs und schreibt gerne über Technologie, Panorama sowie Tipps & Tricks.
Comments (2)
Comments are not enabled for this entry.

Ich fand den Artikel sehr spannend und so geschrieben, das ich auch als Nichtinformatiker, Nichtprogrammierer und Nichtadmin gut folgen konnte.
Ich würde mich freuen, mehr aus diesem Bereich der Informatik zu lesen.
 Viktor Garske
Viktor Garske